
Hello World
I wanted to have an LLM on my phone, cause why not
it’s like a mini-library on your phone which you can talk to, very useful when you’re offline somewhere in the woods
To start I installed Termux on my phone
Note that the version on the Google Playstore is outdated so you will need to get it from the superior Open-Source store that is F-Droid or you can download the Termux apk either directly from the official GitHub Repo
Termux was how I learnt Linux commands, I didn’t even realize they were Linux commands as I never had used Linux before and didn’t have a laptop when I started screwing around on my phone (I know android is technically Linux but it’s not the same)

The first screen is what you will see when you first open it, I installed zsh and oh my zsh with powerlevel10k theme and other features such as auto-suggestion and auto-completion, feel free to ask me for a tutorial on that I would drop one
https://github.com/ggerganov/llama.cpp.git
I’m gonna run the LLMs using llama.cpp, considering how light weight and easy it is to setup, and models are so less complicated to use, the gguf format combine all the model files into one package and pretty much every model you can think of has pre-quantized gguf files ready on hugging face
we have to install some packages on Termux to be able to get going
for that we need to first setup the repos
run
termux-change-repo

and I selected the group rotate and all mirrors so that I could always find a package which could be at least in one of those repos
pkg update && pkg upgrade
ran this to update all the package lists and upgrade existing packages
then installed the packages we need
pkg install wget git clang cmake
wget: to download model files
git: to work with the llama.cpp repo
clang: to compile the code into binaries
cmake: additional tool to be used in the compile process
voila! your Termux setup is ready
Clone the llama.cpp repo
git clone https://github.com/ggerganov/llama.cpp.git
now change your directory into the folder
cd llama.cpp
and compile the binaries
make -j $(nproc)
your bins are ready now we need to get the model, I’m using the qwen2 1.5b param model
https://huggingface.co/Qwen/Qwen2-1.5B-Instruct-GGUF/tree/main
make a folder for it inside the models folder
cd models
mkdir qwen2
cd qwen2
copy the address link of the download button of the quantized version you want and run
make sure to remove the ?dowload=true from the end or it will save it as your-abc-model.gguf/download=true it should have .gguf as the extension
wget https://huggingface.co/Qwen/Qwen2-1.5b-Instruct-GGUF/resolve/main/qwen2-1_5b-instruct-q4_k_m.gguf
you can get the lower precision models which are smaller in size but you will lose quality over performance while running, anything less than q4 is not recommended
now cd back to the root of the repo
cd ../..
and run the following command
./llama-cli -m ./models/qwen2/qwen2-1_5b-instruct-q4_k_m.gguf -n 256 --repeat_penalty 1.0 --color -i -r "User:" -f prompts/chat-with-bob.txt
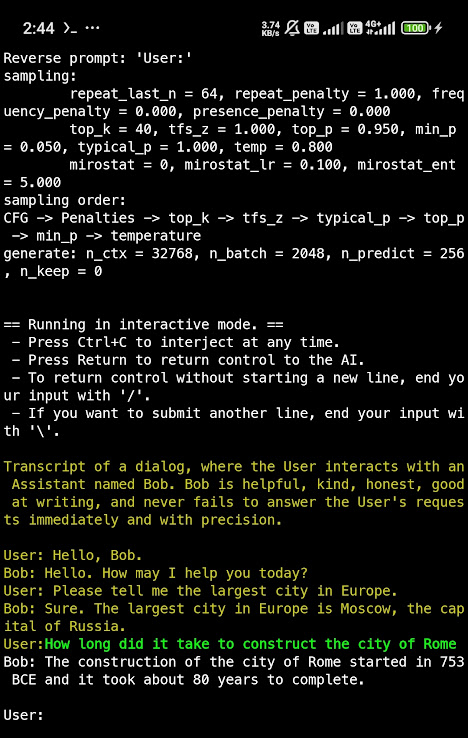
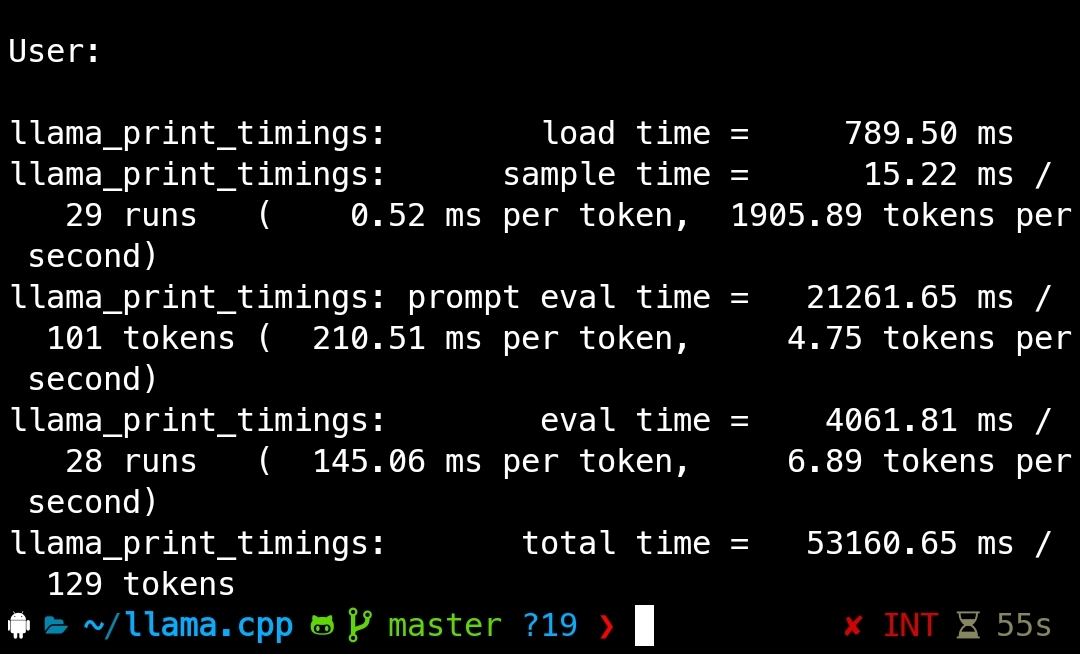
There you go you have your own chatGPT/claude/gemini works completely offline!


评论 (0)