
Tại Sao KIP Là Layer Cơ Bản Cho AI Trong Web3?
Đầu tiên: KIP không phải là một ứng dụng AI đơn lẻ, không phải một mô hình ngôn ngữ lớn, cũng không phải một cơ sở dữ liệu/kiến thức.
KIP là một giao thức phi tập trung mà chủ sở hữu ứng dụng AI 📱, chủ sở hữu mô hình 🤖 và chủ sở hữu cơ sở dữ liệu/kiến thức 🗃️ sẽ thấy quan trọng để phi tập trung công việc của họ và kiếm lợi nhuận trong Web3.
(Để rút gọn, chúng tôi gọi những 3 hạng mục này là: Người tạo Giá trị AI)
Phi tập trung AI là một chủ đề vô cùng quan trọng và lớn, và có nhiều dự án đột phá đang tiếp cận vấn đề theo nhiều cách khác nhau.
Đối với chúng tôi tại KIP, chúng tôi tập trung vào việc giải quyết những vấn đề cơ bản khi Người tạo Giá trị AI cố gắng triển khai và kiếm lợi nhuận từ công việc của họ trong Web3.
MÔ HÌNH AI🤖 CẦN ỨNG DỤNG📱 VÀ DỮ LIỆU🗃️ ĐỂ TẠO RA GIÁ TRỊ KINH TẾ
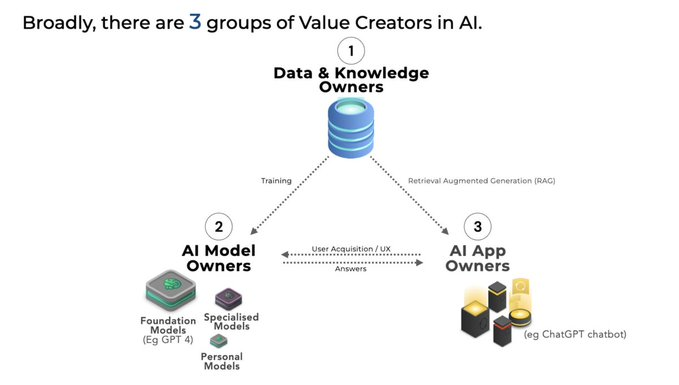
Trong khi có hơn 20 hạng mục công ty tạo ra giải pháp trong lĩnh vực AI, sự chú ý lớn trong AI Tạo sinh suốt năm qua đã tập trung vào các Mô hình AI (và có nhiều hạng mục và phương pháp khác nhau như transformers, GANs, diffusion models để kể một số).
Thực sự, những mô hình này đại diện cho sự đột phá thực sự của thời đại máy tính mới này - bộ não thực sự đằng sau tất cả.
Nhưng để xây dựng một hệ sinh thái kinh doanh trong lĩnh vực AI, các mô hình cần phải phụ thuộc vào ít nhất 2 Người tạo Giá trị cơ bản khác.
- Ứng dụng AI📱**: 'The Face of AI'**
Dễ dàng bỏ qua sự quan trọng của ứng dụng giữa tất cả sự hứng thú về các mô hình.
Ứng dụng AI là thiết yếu để đưa người dùng vào AI. Ứng dụng có thể có nhiều hình thức, như chatbot, tạo hình ảnh, bot tìm kiếm, bot phân tích hoặc ở hình thức tinh tế nhất, chỉ là các lời gợi ý.
Chúng tạo ra trải nghiệm người dùng, thu hút người dùng và có lẽ quan trọng nhất, thu thập phí từ người dùng.
Nhiều người quên rằng ChatGPT là ứng dụng của OpenAI, được cung cấp bởi các mô hình khác nhau của OpenAI (GPT 3.5, GPT 4). Các phản ứng giống con người của chatbot của OpenAI đã được lập trình chủ yếu ở phần ứng dụng, không phải ở phần mô hình. (Kết nối trực tiếp với các mô hình qua API và so sánh các câu trả lời sẽ cho bạn biết điều này.)
TLDR: Không có Ứng dụng, các mô hình chỉ là bộ mã và trọng lượng đang ngồi trong một hộp kim loại ở một nơi nào đó mà không có cách nào sử dụng chúng.
- Dữ liệu🗃️: 'The Lifeblood of AI'
Dữ liệu cần thiết cho:
a) Huấn luyện và Tinh chỉnh Mô hình
b) Sinh sản theo yêu cầu (RAG)
Tất cả các mô hình đều được đào tạo và điều chỉnh tốt trên dữ liệu. Mà không có tinh chỉnh, mô hình không trở nên mạnh mẽ hoặc thông minh hơn.
Nhưng bằng cách sử dụng dữ liệu để điều chỉnh hoặc đào tạo mô hình, nó làm cho dữ liệu thực sự được 'hấp thụ' hoặc 'hấp thụ' vào các mô hình, thể hiện trong việc điều chỉnh trọng số của mô hình.
Do đó, trong những tình huống mà việc chỉ sử dụng dữ liệu để trực tiếp đào tạo mô hình là không thể, không thực tế hoặc bất hợp pháp, phương pháp độc đáo được gọi là "Retrieval-Augmented Generation" (RAG) bước lên để cung cấp.
RAG kết hợp sức mạnh của việc truy xuất thông tin từ các cơ sở dữ liệu bên ngoài với khả năng tạo ra câu trả lời thông qua một Mô hình AI. Đó như là có một trợ lý siêu thông minh hiểu câu hỏi của bạn nhưng cũng biết nơi để tìm câu trả lời ngay cả khi nó không biết câu trả lời.
Trong khi RAG vẫn còn mới, chúng tôi tin chắc rằng với sự nhạy cảm và bảo vệ dữ liệu ngày càng tăng, các kỹ thuật RAG có thể trở thành một phương pháp tiếp cận hàng đầu, đẩy mạnh giá trị kinh doanh đối với ứng dụng thực tế và làm cho nó trở thành một khung cảnh chiếm ưu thế mà dưới đó hầu hết mọi người tiếp cận AI trong tương lai.
TLDR: Bất kể phương pháp nào, sự đổi mới liên tục trong lĩnh vực AI đều không thể có được mà không có dữ liệu.
MỘT HỆ SINH THÁI AI SÔI ĐỘNG YÊU CẦU NHIỀU NGÀNH NGHỀ CÓ GIÁ TRỊ ĐỘC LẬP
Cá nhân và công ty có kỹ năng đào tạo và điều chỉnh mô hình có thể không phải là những người xuất sắc trong việc thiết kế và tiếp thị ứng dụng phục vụ khách hàng. Tương tự, các nhà nghiên cứu và chuyên gia lĩnh vực có bộ dữ liệu và cơ sở kiến thức có giá trị có thể không có các kỹ năng phù hợp để đào tạo mô hình AI hoặc thiết kế ứng dụng.
Nhưng trong một hệ sinh thái đa dạng và đa dạng, họ không cần phải làm điều đó. Các ngành công nghiệp và cá nhân độc lập có thể hợp tác để tạo ra các trường hợp sử dụng và giá trị kinh tế cho người dùng.
Một nhà thiết kế ứng dụng có thể chọn mô hình AI phù hợp nhất cho kế hoạch sản phẩm của mình và trước chọn các cơ sở kiến thức bên ngoài hữu ích nhất cho người dùng của mình.
Nhưng nếu tất cả 3 ngành công nghiệp có thể đa dạng và độc lập có thể đang từ từ được hấp thụ vào một hệ sinh thái đóng, đó là chính xác điều đang xảy ra ngay bây giờ. Chúng tôi sẽ trình bày điều này chi tiết trong các bài viết sắp tới, nhưng hiện tại: hãy tìm kiếm trên web từ khóa "openai copyright shield" và xem xét ý nghĩa đối với quyền sở hữu dữ liệu trong tương lai AI.
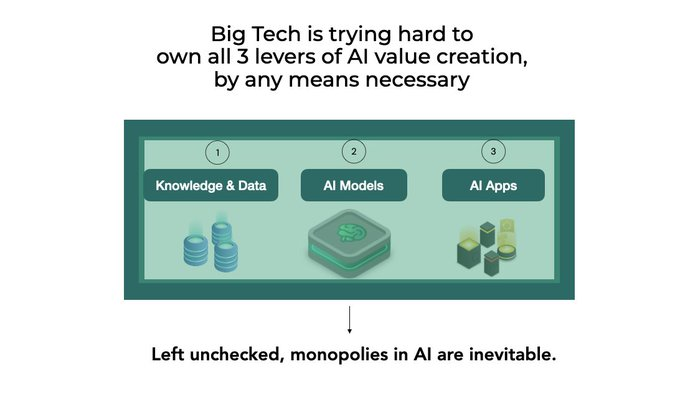
TẠI SAO KIP MUỐN KHÍCH LỆ TÍNH PHI TẬP TRUNG CỦA AI
Quyền độc quyền trong AI đặc biệt nguy hiểm, và phi tập trung AI là một phản ứng cần thiết và khẩn cấp trước sự khuất phục của lợi ích chung của chúng ta trước một tập hợp hẹp các lợi ích doanh nghiệp.
Chúng tôi 100% ủng hộ "gia tăng AI" (e/acc) và chúng tôi không phủ nhận những đóng góp đáng kể của Big Tech trong việc thúc đẩy đổi mới AI.
Nhưng các công ty lớn chỉ hành động trong lợi ích tốt nhất cho cổ đông của họ, và họ sẽ làm bất cứ điều gì mà họ có thể thoát khỏi. Đó là bản chất của vốn, mong đợi họ thay đổi bản chất và bỏ qua động cơ đầu tiên của họ là từ chối hiện thực.
Chúng ta cần một trạng thái cân bằng đối địch trong AI, với nhiều tác nhân khác nhau tham gia và cạnh tranh trên thị trường, tạo ra một môi trường mà đổi mới có thể phát triển. Tương lai của AI không được làm cho khuất phục dưới sự lợi ích doanh nghiệp của bất kỳ tập đoàn lớn nào.
Và phi tập trung AI là, theo quan điểm của chúng tôi, LÀ ĐƯỜNG DUY NHẤT để mang lại trạng thái mong muốn đó.
LÀM THẾ NÀO KIP KÍCH THÍCH TÍNH PHI TẬP TRUNG CỦA AI

KIP giải quyết ba vấn đề cơ bản mà ứng dụng AI, mô hình và chủ sở hữu dữ liệu sẽ phải đối mặt khi cố gắng phi tập trung.
-
Kết nối On-chain / Off-Chain
-
Kiếm lợi và Kế toán
-
Quyền sở hữu và Bảo mật
Vấn đề "Kết nối"
Có hơn 400,000 mô hình trên Hugging Face, điều này cho thấy mức độ sôi động, nhưng cũng là sự non trẻ của toàn bộ ngành công nghiệp AI.
Công nghệ blockchain hiện tại không thể cung cấp chức năng suy luận cơ bản của mô hình (tức là mô hình hoàn toàn phi tập trung) với chi phí hoặc tốc độ mà hầu hết người dùng bình thường sẽ chấp nhận được (mặc dù tiến bộ trong tính toán biên có thể đưa chúng ta đến đó sớm).
Do đó, hầu hết, nếu không phải tất cả, các mô hình này đều nằm ngoài chuỗi, và chúng ta có thể mong đợi nhiều đổi mới và thử nghiệm sẽ được thực hiện ngoài chuỗi.
Để phóng tất cả những ý tưởng và đổi mới đó trong web3, KIP làm cho việc tính toán nặng nề liên quan đến suy luận học máy có thể được xử lý ngoài chuỗi, trong khi vẫn duy trì tính toàn vẹn và nguyên tắc của một hệ thống phi tập trung.
Vấn đề về "Tiền"
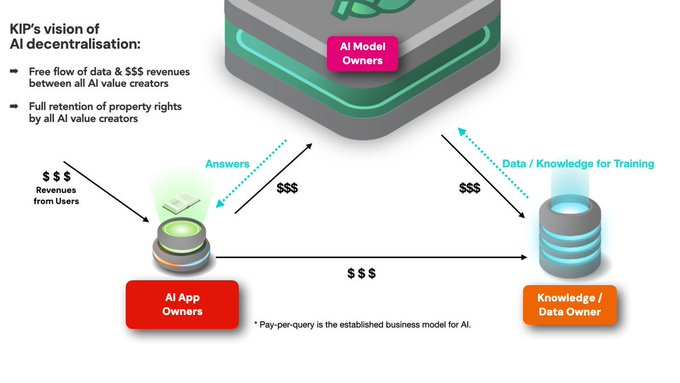
Công nghệ tốt nhất trên thế giới cũng sẽ không được chấp nhận nếu người áp dụng không có lợi ích kinh tế tăng.
Khung mô hình thu nhập cơ bản cho AI có thể được mô tả như "trả theo truy vấn", vì mỗi truy vấn duy nhất từ người dùng tiêu tốn tài nguyên GPU, và do đó phải được thanh toán bởi ai đó. Và để trả lời một truy vấn duy nhất của người dùng, nhiều Người tạo Giá trị AI đóng góp vào việc trả lời câu hỏi đó.
Chúng tôi không khuyến khích sự phi tập trung chỉ vì sự phi tập trung, mà là phi tập trung như một phương thức thay thế cho sự độc quyền.
Do đó, để phi tập trung AI thành công, chúng ta cần đảm bảo rằng những bên đang phi tập trung công việc AI của họ có thể kiếm lợi nhuận.
Điều này nghe có vẻ rõ ràng, nhưng trong trường hợp của AI, điều này không phải lúc nào cũng đơn giản như vậy.
Hãy xem xét một ví dụ về một truy vấn được thực hiện thông qua RAG
-
Người dùng đưa ra một truy vấn cho Chatbot AI.
-
Chatbot AI chuyển truy vấn đến não bộ của nó, mô hình AI.
-
Mô hình truy xuất chỉ các phần dữ liệu liên quan từ Cơ sở Kiến thức mà nó cần để trả lời câu hỏi, đưa ra câu trả lời và gửi lại cho Ứng dụng.
-
Ứng dụng đóng gói câu trả lời và gửi lại cho người dùng.
Trong ví dụ đơn giản này, bạn sẽ thấy cách tất cả 3 đối tác đều đóng góp vào việc trả lời câu hỏi của người dùng.
Nếu một nền tảng sở hữu và kiểm soát tất cả ba (🤖,📱,🗃️) trong một hệ sinh thái tập trung (như OpenAI đang cố gắng làm trong biểu đồ thứ hai ở trên), thì bạn chỉ cần thanh toán cho nền tảng tập trung đó một cách dễ dàng, vì phần còn lại là kế toán nội bộ.
Nhưng nếu chúng ta muốn phi tập trung thay vì độc quyền, thì mỗi bên cần được thanh toán, đòi hỏi giải pháp cho:
-
Ghi (on-chain) các đóng góp của mỗi bên,
-
Phân chia/gán lợi nhuận từ người dùng
-
Cho phép mỗi bên rút lợi nhuận của họ
Đây là "vấn đề tiền" trong việc phi tập trung AI mà KIP giải quyết.
Chúng tôi làm điều này thông qua một cơ sở hạ tầng Web3 hiệu suất cao, chi phí gas thấp cung cấp kết nối giữa Người tạo Giá trị AI, cách thu tiền từ người dùng và cách rút lợi nhuận. (Chúng tôi sẽ đề cập đến điều này trong một bài giải thích KIP sắp tới)
Mà không giải quyết vấn đề tiền trước, việc phi tập trung AI sẽ khó khăn hơn nhiều và sẽ ít có khả năng được chấp nhận rộng rãi hơn ngoài vài người tin tưởng.
Vấn đề "Quyền sở hữu"
Kiếm lợi chỉ là đặc quyền yếu nhược, nếu nó không liên quan đến quyền sở hữu thực sự.
Chúng ta đã thấy làm thế nào tài khoản trên các nền tảng tập trung có thể bị đóng cửa, cấm, hay bị "shadowbanned" bất cứ lúc nào.
KIP giải quyết vấn đề này bằng cách sử dụng mã thông báo blockchain, cụ thể là mã thông báo ERC-3525 (SFTs), để "bọc" công việc của Người Tạo Giá Trị AI.
-
Đối với chủ sở hữu dữ liệu: SFTs bọc các cơ sở kiến thức được vector hóa, hoặc một liên kết đến một tệp dữ liệu raw được mã hóa để sử dụng cho việc đào tạo mô hình.
-
Đối với người làm mô hình: SFTs có thể bọc một API đến một mô hình off-chain, hoặc một bộ trọng số mô hình sẵn sàng để bán
-
Đối với nhà phát triển ứng dụng: SFTs có thể bọc các API front-end, hoặc chính đề mục của ứng dụng.
Những SFTs này hoạt động như 'thực thể kế toán' có thể tương tác với nhau trên chuỗi và ghi lại số lượng mà mỗi SFT kiếm được từ một giao dịch cụ thể.
Bằng cách giải quyết những vấn đề này, KIP tạo điều kiện cho Người Tạo Giá Trị AI dễ dàng phi tập trung công việc của họ, tạo ra điều kiện khởi đầu cho một hệ sinh thái trí tuệ nhân tạo phi tập trung và lớn mạnh hơn.
KIP là Layer Cơ Bản Web3 cần thiết cho trí tuệ nhân tạo.


评论 (0)