
EOF or EVM Object Format is a proposed set of upgrades to EVM(Ethereum Virtual Machine), planned to be included in the upcoming hardforks. It standardises a way to encode the bytecode of a smart contract in a more structured manner.
Its one of the biggest changes to the EVM since the genesis of Ethereum. In this article we shall go through the current way in which the bytecode is structured (hereafter called legacy code), the problems it has and why we need EOF and how EOF solves some of the problems of legacy code.
What do we have currently?
Before we can start with changes EOF brings, we must first understand how the current legacy system works. We'll be using this following contract and its bytecode as example in this section.
// SPDX-License-Identifier: MIT
pragma solidity 0.8.21;
contract BaseIncrement {
uint256 num;
bytes32 constant digest = 0x04485b22a670ade5407e78fb2863c51de9fcb96542a07186fe3aeda6bb8a116d;
bytes32 storageDigest;
function increment() external {
storageDigest = digest;
num += 1;
}
}
Its a very simple contract which has storage variable num, storageDigest and a function increment which when called increments the storage variable num and stores the constant variable digest as storageDigest.
Current Solidity code format
When you compile this code, you get the following bytecode which is deployed.
deployed byetcode - 6080604052348015600f57600080fd5b506004361060285760003560e01c8063d09de08a14602d575b600080fd5b60336035565b005b7f044852b2a670ade5407e78fb2863c51de9fcb96542a07186fe3aeda6bb8a116d6001908155600080548190606a9084906071565b9091555050565b80820180821115609157634e487b7160e01b600052601160045260246000fd5b9291505056fea264697066735822122093ad1a84e1cc5f50d88cb85b1f30eb2db6a5e64558983cd6e8e5b4623c3df29f64736f6c63430008150033
When this function is called at runtime, the execution of the bytecode starts from the beginning and continues until its stops execution by the STOP opcode, or reverts or the code ends.
If you have good knowledge of the EVM and how to read byetcode, you can compute through the above bytecode and be able to split it up into sections as follows
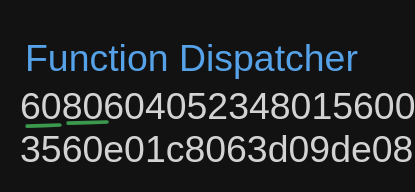
Function Dispatcher- 6080604052348015600f57600080fd5b506004361060285760003560e01c8063d09de08a14602d575b600080fd
Increment code logic- 5b60336035565b005b7f044852b2a670ade5407e78fb2863c51de9fcb96542a07186fe3aeda6bb8a116d6001908155600080548190606a9084906071565b9091555050565b80820180821115609157634e487b7160e01b600052601160045260246000fd5b9291505056
Data section containing ipfs hash, solidity compiler version etc- fea264697066735822122093ad1a84e1cc5f50d88cb85b1f30eb2db6a5e64558983cd6e8e5b4623c3df29f64736f6c63430008150033
The first is the function dispatcher segment, this looks at the function signature in the calldata of the transaction and routes the execution of the code to the relevant part of the bytecode. Second is the bytecode for the increment function.
Lastly, the third section of the bytecode is just metadata about this contract, it contains things like the solidity compiler version, ipfs hash of the compiler settings etc. The third section is generated by the solidity compiler automatically and attached to the end of the bytecode. This helps verify the contract and in code analysis.
This third data section is never executed, the bytecode is set so that all executions reverts or stops before reaching this section of the code.
Keep in mind that this way of adding metadata to the end of the contract is just how solidity adds metadata, other EVM smart contract languages like Vyper might do it differently. It is not a standard, the code will run perfectly fine even without this third section. The metadata can be placed in between actual executing bytecode as well, it doesn't only have to be in the end.
Push and Immediate arguments
Before we go to the next section, it is vital to understand push opcode and immediate arguments.
Push is a opcode used to push a certain length of bytes after it into stack memory. We don't have to go into stack memory here. All we need to understand is push opcodes have arbitrary arguments immediately after it in the bytecode, and these can be anything. These are immediate arguments.
In the above picture, the highlighted bytecode 60 is the opcode for Pushing 1 byte to the top of the stack. And the highlighted bytecode 80 is the bytecode which will be pushed to the top of the stack. This 1 byte of data can be any byte.
Jumpdest Analysis
The compiler compiles the code in such a way that according to the calldata input given the execution has to jump back and forth between different parts of the bytecode. For example in the function dispatcher section from above, once the function selector in the calldata is determined it jumps execution from the function dispatcher section to the section containing the increment logic.
It happens at

When the function selection in the calldata is correct only the bytecode highlighted in green is executed, then it jumps to the section containing the logic. To stop the execution to jump to arbritrary parts of the code, the EVM currently only allows jumps to the jumpdest opcode. Jumpdest opcode is 5b. That is the EVM only allows jumping the execution to where it contains 5b, like shown below.
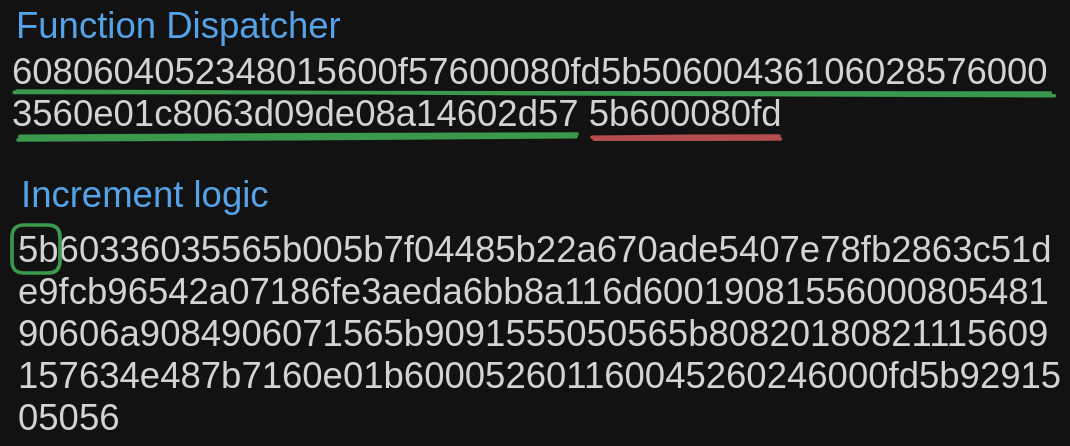
After the execution of the function dispatcher section highlighted in green, the execution jumps to the jumpdest opcode 5b at the start of the increment logic section.
So does all 5b in the bytecode denote valid jump destinations?
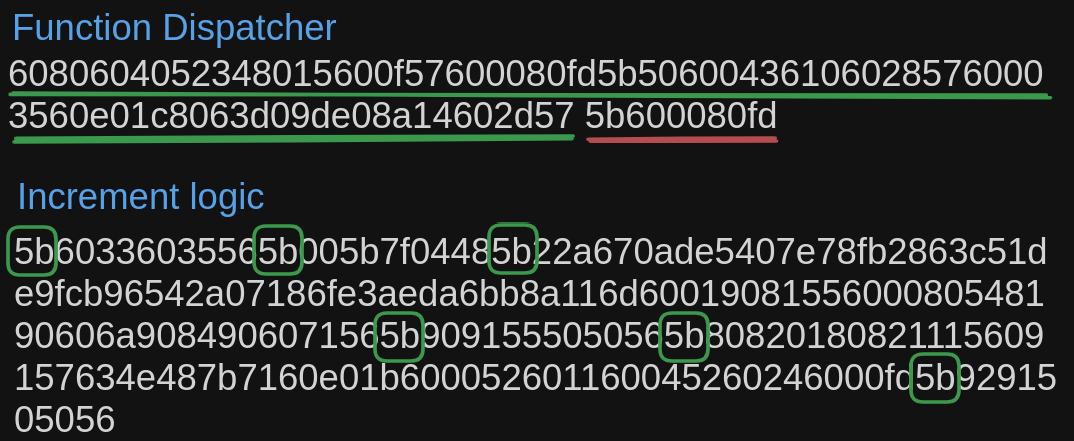
The answer is no. Not all 5b in the opcode can automatically be considered a valid jump destination. Because as we saw in the previous section on PUSH opcodes and immediate arguments, any byte can be add to be pushed onto the stack using PUSH. And the third 5b in the bytecode shown below is not valid jump destination but part of the immediate argument for a PUSH32 opcode.
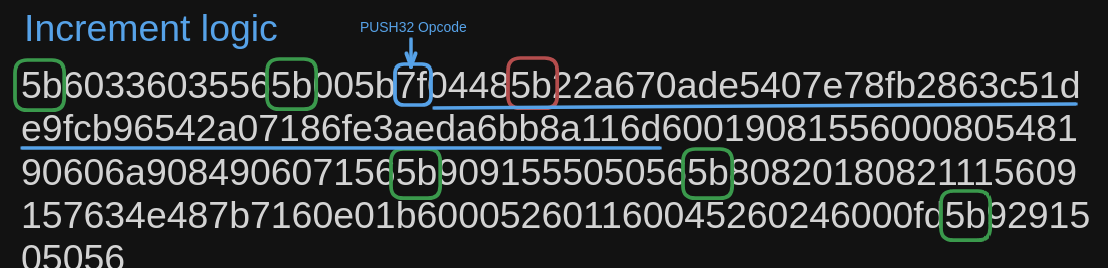
As you can see in the above picture, the PUSH32 opcode and the red highlighted 5b is part of the immediate argument for it and hence not a valid jump destination.
To avoid problems arising from the edge case, ethereum exectuion clients like geth and nethermind etc, do something called a jumpdest analysis which analyses the bytecode before every execution to find the valid jumpdest opcodes. This is an extra computation which might slow down the execution of transactions.
Allows Arbitrary Hex to be in Bytecode
Currently, there is no validation during contract deployment time to ensure that all the hex in the bytecode is a valid OPCODE or immediate argument accepted in the EVM. There might be invalid opcode in the bytecode and it will not throw any errors during runtime as long the execution jumps/avoids the invalid opcodes. But the problem with this current approach is that it makes it really hard to make upgrades and changes to the EVM, as it might make these invalid opcodes valid. This can breaks existing contracts.
Why do we need EOF?
As we saw in the above sections the current EVM is not perfect and has certain drawbacks we would want to overcome. By adding EOF support we can have
-
Upgradeability of the EVM
-
Code and data separation
-
Eliminate JUMPDEST and replacement it with code sections
How EOF Works
Henceforth in this article, we'll be referring to the current EVM as legacy to clearly differentiate it with the proposed EOF changes.
In the Legacy EVM, all the bytecode deployed in assumed to be valid and is executed serially from the beginning of the bytecode till the end or until it reverts or execution stops. There is no validation of the code during runtime and no enforced code and data separation.
In EOF, the concept of unstructured contracts is replaced with containers. These containers are structured bytecode which contain the version of the EOF it runs, the number and size of code sections it has, the stack inputs, outputs for each code section and also a separate data section which can contain etc.
The EOF container is structured as
container = Header, Body
header :=
magic, version,
types_section_id, type_section_size,
code_section_id, num_code_sections, code_sizes,
[container_section_id, num_container_sections, container_section_sizes,]
data_section_id, data_section_size,
terminator
body := types_section, code_sections, [container_section], data_section
types_section := (inputs, outputs, max_stack_height)+
note: In the above block , is a concatenation operator, + should be interpreted as “one or more” of the preceding item, and anything within [ ] should be interpreted as an optional item.
The Magic is the 2-byte long unique identifier to establish that this is an EOF container. The EOF Version is 1-byte defining the version of the EOF used in the container.
The Headers define the type, number and length of sections in the body of the container. There are multiple types of sections which can be defined in the headers.
-
Types Section - Contains the number of inputs, max stack height of a code section and whether it is non-returning.
-
Code Section - The sections actually contain the code which is run during execution.
-
Subcontainer Section - These sections contain bytecode of contracts which are to be deployed by the container.
-
Data Section - These sections contain arbitrary data, which might contain the compiler version and other metadata about the container
The Headers are followed by a header terminator of 00 to denote the end of the headers and beginning of the sections. The sections are arranged in the order of Types, Code, Subcontainer and Data.
The headers for the types, code and data sections are mandatory.
EOF Structure
All EOF container must start with the magic and version, The magic as proposed in EIP3560 is EF00 which is 2 bytes long. The version of the EOF should be 1 byte long. An EOF container starts as follows-
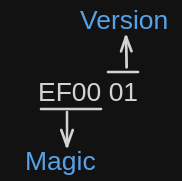
Headers of the Container
After the Magic and Version the headers begin. The first is the header for the types section. The id for the type section header is 01. The Id is followed by the length of the type section in 2-byte.

From the above section we know that the type section has length of 4 bytes.
The code section header is added after the type section header.
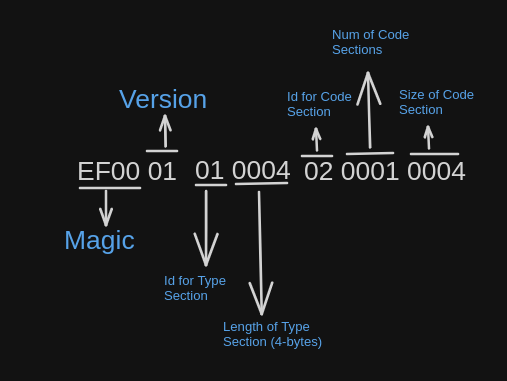
As you can see above, the id for code section header is 02 and its followed by 2 bytes indicating the number of code sections. Which in turn is concatenated with 2 bytes containing the size of the code section. If there are more than 1 code section, the 2 bytes for the sizes of each of the code sections is concatenated.
Next for the subcontainer header,
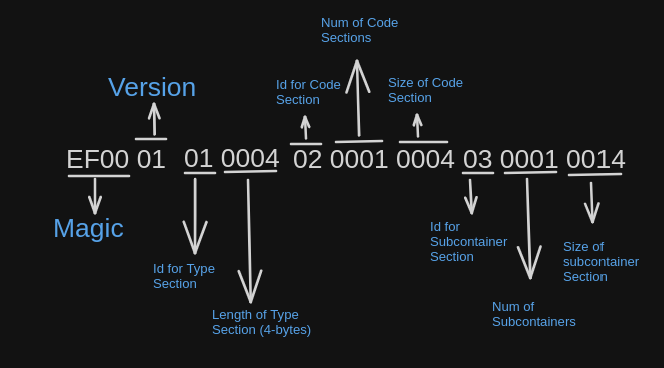
As shown in the above diagram, the id for denoting the subcontainer header is 03 and it followed 2 bytes denoting the number of subcontainer section. After that, 2 bytes denoting the length of each of the subcontainer sections is added.
Finally, at the end of the headers is the header for the data section
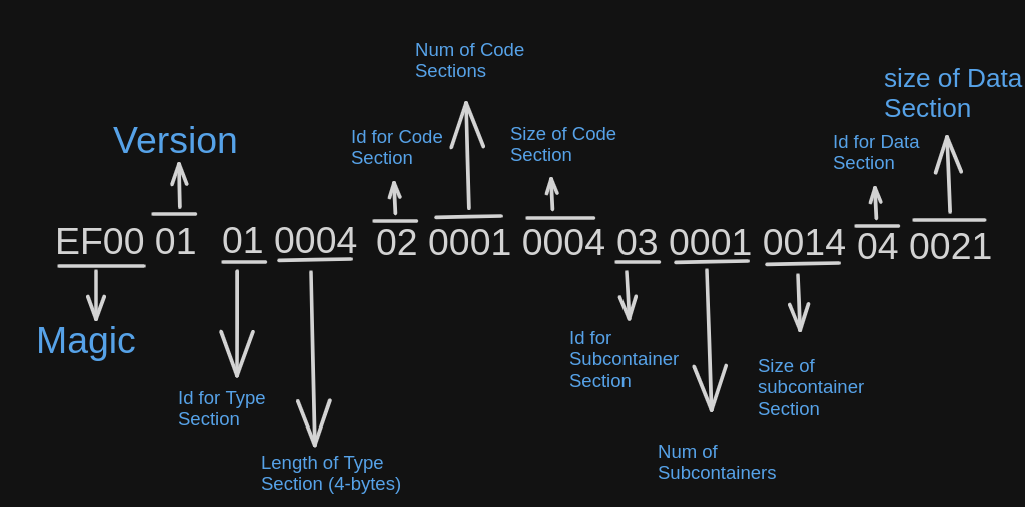
The id for the data section is 04, which is followed by 2 bytes denoting the size of the data section
The Header is terminated with 00
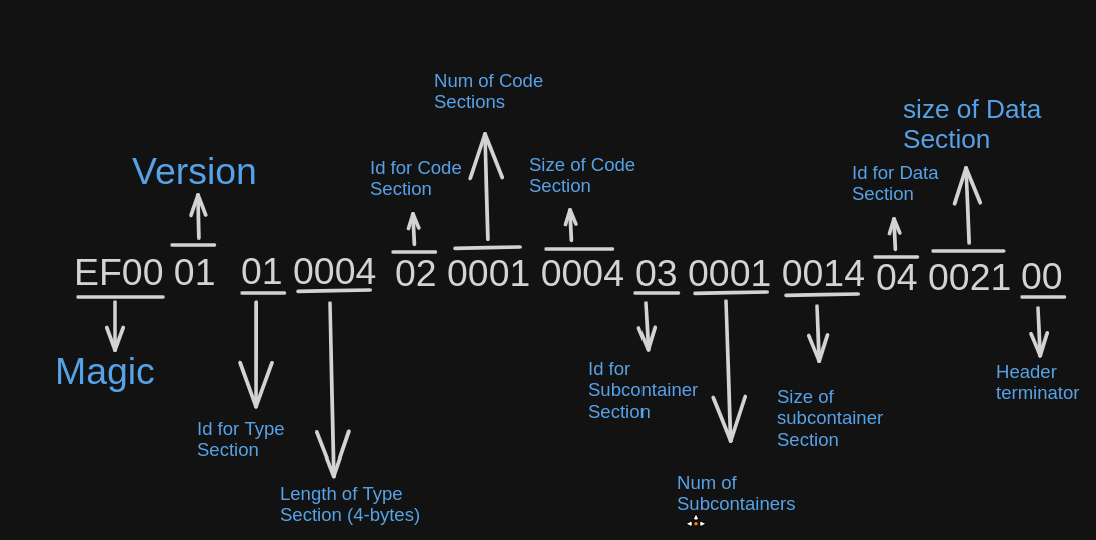
Now that the headers are done, after this point in the bytecode, the body of the container begins
Body of the Container
The body of the container contains the actual content of the all the sections defined in the above headers.
The sections are arranged in the same order the headers are, that is types, code, subcontainer and data sections.
The type section is added as follows
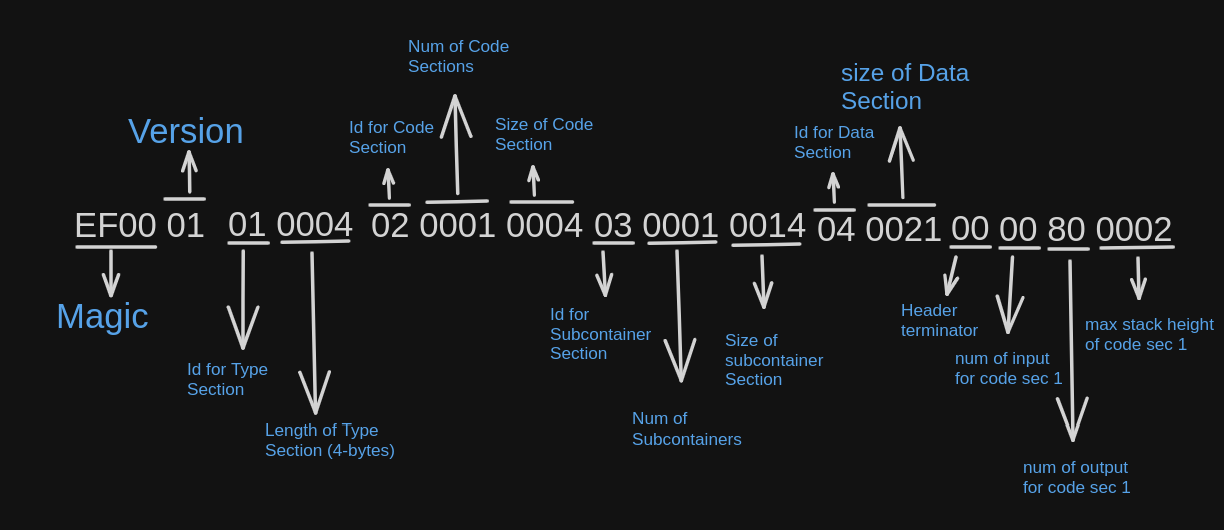
As you can see above, the type section defines the number of inputs(1 byte), number of outputs(1 byte, 0x80 if its non-returning), and max stack height(2 bytes) of all the code sections. In the above example since only one code section is specified in the headers only the number of input, outputs and max stack height for one code section is present in the types section.
The types section is followed by the code section,
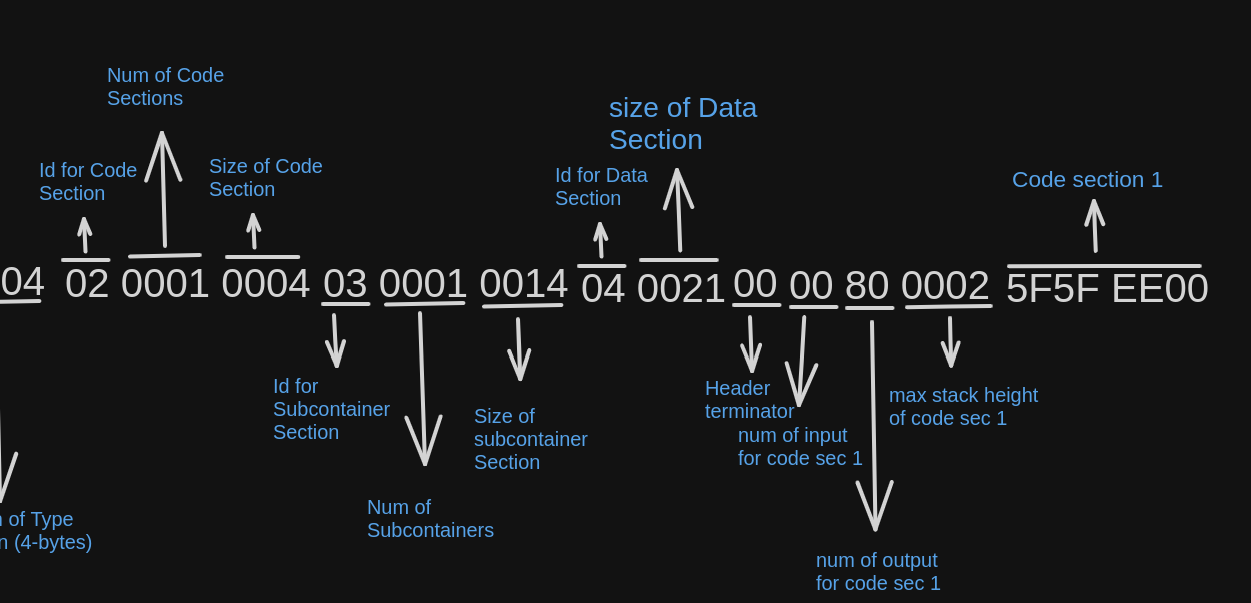
As defined in the header, there is only one code section and it is of length 4 bytes.
This code section is where the actual bytecode which is executed it present. In EOF, the code sections can only contain valid opcodes. This validation happens during deploy-time and if some invalid opcodes are detected the container deployment is reverted.
Due to this validation only currently valid opcodes can be present, and in the future new opcodes can be added without it breaking previous contracts.
Also another EIP in EOF, removes support for JUMP and JUMPDEST in EOF container, and code execution can only jump from one valid code section to the beginning of another code section. Hence JUMPDEST analysis is not needed before runtime.
After the code section, the subcontainer section is added to the container. The subcontainer section consists of the bytecode of the child container/contract the parent contract has to deploy. For example, a factory contract which creates other contracts, contains the bytecode of the deploying contract in the subcontainer section.
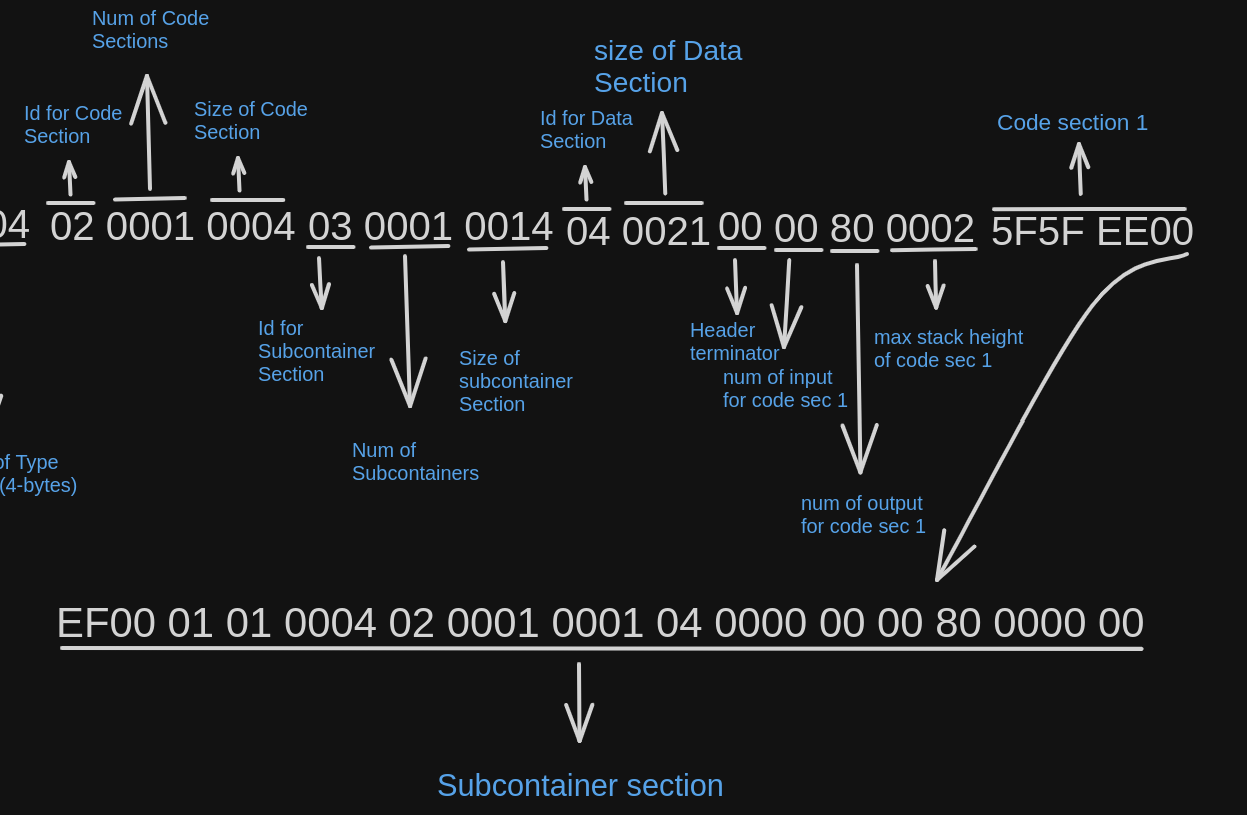
As shown in the above image, the subcontainer contains the EOF bytecode for its own container. Unlike the other sections the subcontainer section is optional
After the subcontainer section, the data section is appended,
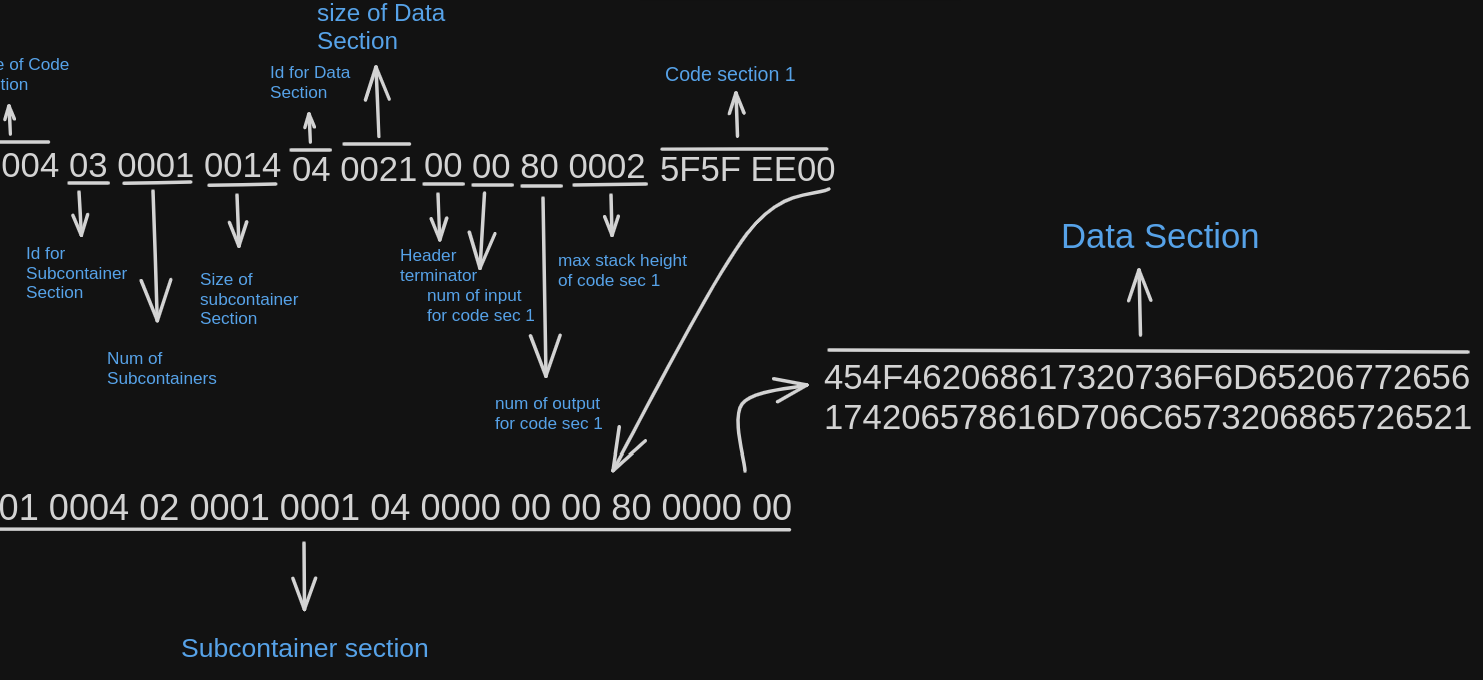
The data section can contain as arbitrary bytecode which might contain more information and metadata about the container.
You can more examples EOF containers and how they are split here.
Conclusion
Now we have an brief understanding of the proposed EOF upgrade to the EVM and how it is to be structured. I hope this article has helped you better understand EOF.
I've attached other resources I used to learn about EOF in the References below. Give them a view as well if you feel some of the concepts in this article are not well explained.
References
-
Rareskills Blog on Solidity Metadata- https://www.rareskills.io/post/solidity-metadata
-
Uttam Singh's Youtube Video on EOF- https://www.youtube.com/watch?v=3-bAWOBemyc
-
Ethereum Cat Herders Youtube Video on EOF with Danno Ferrin - https://www.youtube.com/watch?v=rlZwPuF149U
-
EOF container Examples- https://github.com/ethereum/evmone/blob/master/test/unittests/eof_example_test.cpp


评论 (0)