
Jeff Liu,Oliver Peng,Analyst
A recent study titled "From News to Forecast: Iterative Event Reasoning in LLM-Based Time Series Forecasting", co-authored by Professor Junhua Zhao’s group at The Chinese University of Hong Kong, Shenzhen and Professor Jing Qiu’s team at the University of Sydney, has been accepted by NeurIPS, one of the top-tier conferences in artificial intelligence. This paper introduces a new paradigm for time series prediction, which involves using large language models to predict time series data based on news text. According to the training and validation of datasets such as electricity load, exchange rates, and Bitcoin prices in the paper, the time series prediction method driven by news events and large language models outperforms existing methods, fully demonstrating the potential of integrating alternative text information like news in the field of crypto quantification.
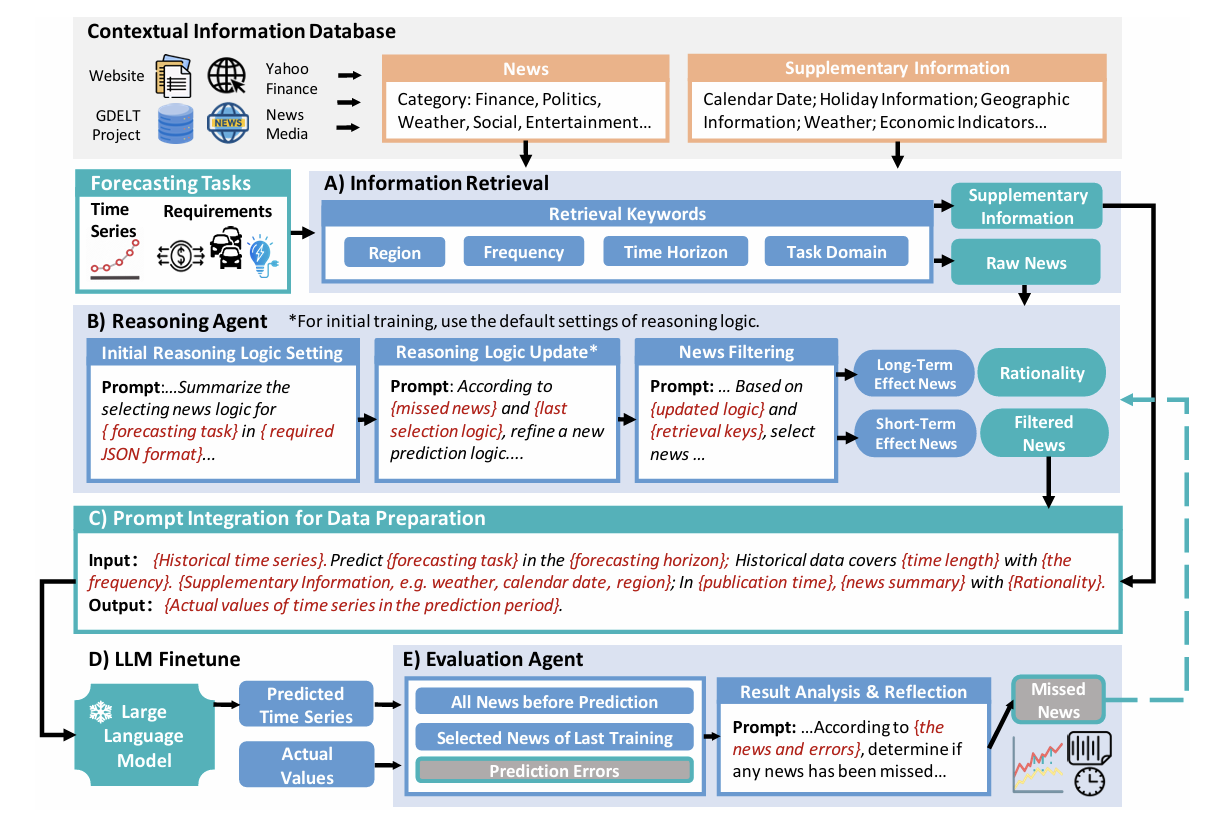
The proposed forecasting framework consists of four key stages:
1. Information Retrieval Module – Extracts relevant news and contextual data (e.g., weather, geographical, economic indicators) from sources like GDELT and Yahoo Finance.
2. Reasoning Agent Construction – Employs LLMs to iteratively screen and classify news items based on their relevance and temporal impact (short-term vs. long-term).
3. Data Fusion and LLM Fine-tuning – Integrates filtered news, auxiliary context, and historical time series into structured prompts; the LLM is then fine-tuned to model the conditional probability of future sequences.
4. Agent Optimization via Error Feedback – Forecasting performance is used to update and refine the reasoning agent, enabling a closed-loop system of continuous improvement.
This work illustrates the feasibility and advantages of integrating natural language processing techniques into financial time series forecasting, particularly in high-volatility domains such as cryptos.
2. Technological Innovation
2.1 Reconstructing the Framework of Time Series Forecasting
Traditional time series prediction tasks typically utilize the numerical characteristics of time series, leveraging the autoregressive characteristics of time series or introducing exogenous variables combined with numerical methods for prediction. However, the paper innovatively views time series as "digital token sequences," utilizing the text sequence generation capability of LLMs for prediction. Traditionally, LLMs essentially output the next character with the highest conditional expectation given the preceding text, which is analogous to time series prediction tasks. Assuming there is a time series {"123", "456"}, the probability of predicting "456" given the character sequence "123" can be expressed as an autoregressive probability prediction process:


2.2 News Filtering, Aggregation, and Inference Analysis Based on Large Language Model Agents
Although large language models (LLMs) possess certain capabilities in generating time series forecasts, performing few-shot prediction directly from raw time series and associated news data remains challenging. First, generating numerical tokens is inherently difficult for LLMs, as numbers are relatively rare in their training distributions. Second, the relationship between news events and time series trends often requires inductive reasoning from historical patterns—something that falls beyond the standard scope of few-shot learning in LLMs.
To address these limitations, the authors employ a supervised instruction-tuning approach, pairing time series data with relevant news information and formatting them as input-output text sequences. Fine-tuning is conducted using Low-Rank Adaptation (LoRA). However, unfiltered or irrelevant news may introduce significant noise, potentially degrading prediction performance. Therefore, the method integrates a Reasoning Agent and an Evaluation Agent to ensure data quality and optimize the system iteratively.
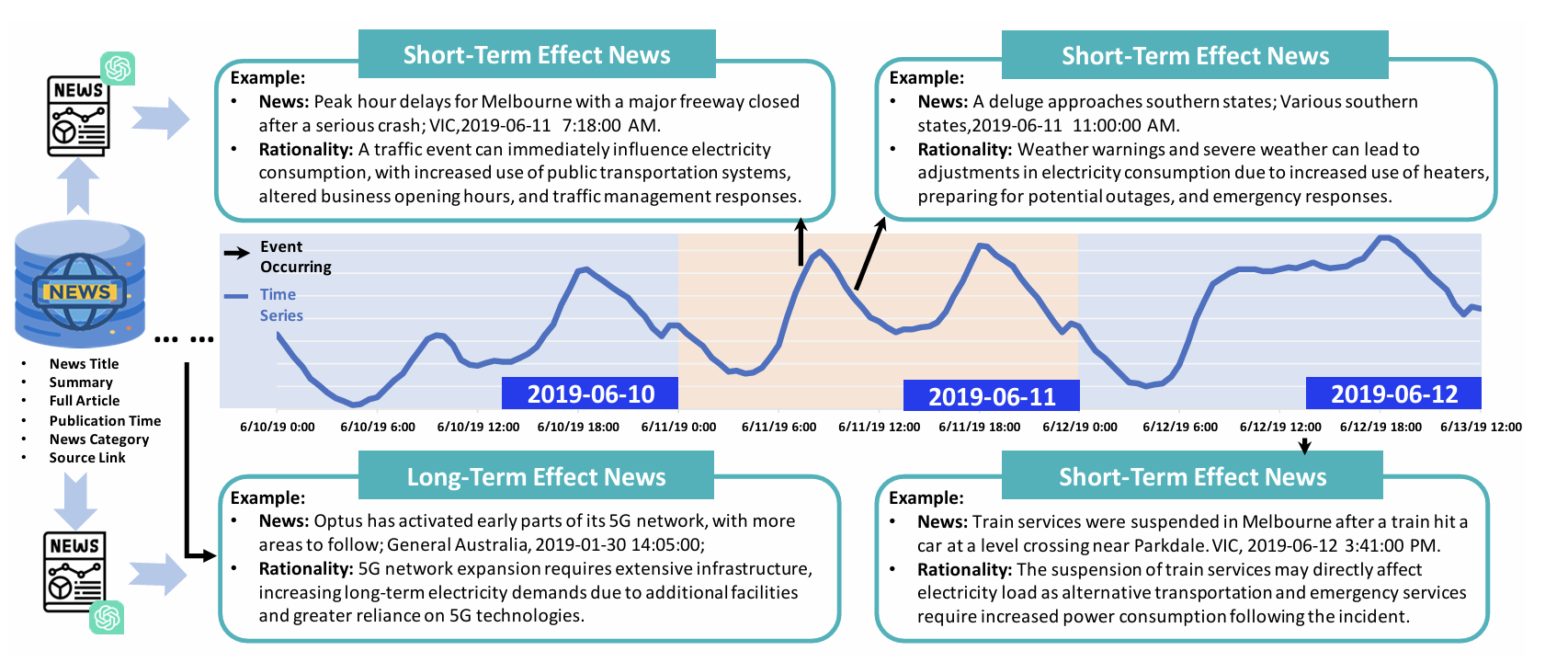
Specifically, in the initial iteration, the LLM develops a domain-specific news filtering logic based on the forecasting task and relevant time frames. The Reasoning Agent filters and aligns news data with time series inputs for initial fine-tuning. At each iteration, a validation set is sampled from the training corpus to test model predictions. The Evaluation Agent identifies potentially omitted but impactful news items, feeding this feedback back into the Reasoning Agent to refine its filtering criteria. Through iterative loops, the Reasoning Agent incrementally constructs an optimized, context-aware news filter for final deployment.
3. Co Indicator Related
3.1 Constructing New Co Indicators (A Simple Proposal)
We can draw on the framework of "event screening, reasoning, and filtering + prediction, reflection, and improvement" from the literature: First, prepare the definitions of existing co indicators, business objectives, community discussion texts, and typical crypto news events as prompts. Then, let the LLM generate new indicators based on these inputs, including names, definitions, suggested calculation formulas, and explanations of business value. Through this method, the LLM can learn from the existing co indicators provided, combining unstructured information and numerical features from user discussions to design new candidate indicators in dimensions such as cross-platform comparisons, user segmentation, and emotional dynamics.
Next, we can use the LLM's multi-step reasoning (Chain-of-Thought) to automatically evaluate the innovativeness, explainability, and computational feasibility of these new indicators, selecting the most promising candidate features. Finally, by combining feedback from analysts and validating results with historical data, we can iterate multiple times to continuously improve the quality and business relevance of the generated indicators. Ultimately, new co indicators will be formed.
3.2 Deep integration with the CO indicator dataset
The referenced study employs an LLM-based, news-augmented framework to forecast Bitcoin price time series, achieving performance that surpasses conventional predictive models. Within this LLM + News + Time Series architecture, the model leverages the powerful reasoning capabilities of LLMs to form a closed-loop process of event selection → causal inference → predictive generation. This approach not only enhances forecasting accuracy but, more importantly, demonstrates how external textual events can be systematically transformed into structured model inputs. The LLM is capable of autonomously interpreting and reasoning about the latent relationships between these events and quantitative dynamics. This aligns closely with the underlying philosophy of our CO indicator system.
In particular, within the highly volatile and sentiment-driven crypto market, textual signals can effectively compensate for the limitations of traditional price- and volume-based indicators, unlocking vast application potential for the CO dataset. A key challenge in the paper's methodology lies in supplying the reasoning agent with valuable and relevant textual inputs. The CO dataset’s time-series database of financial sentiment, derived from private-domain data sources, ensures both the quality and informativeness of the textual input. It also saves users the significant effort of sourcing and preprocessing external news data. Furthermore, some components of the CO dataset are proprietary and unavailable through public channels, offering unique signal advantages for crypto time series prediction tasks.
3.2.1 Design of a Crypto Quantitative Model Training Framework Integrating Private-Domain Data
Following the prompt engineering approach used for training and fine-tuning reasoning agents in the referenced literature, a structured prompt can be constructed based on the unique features of the CO dataset as follows:
Input Integration (Forecast Agent)
{Historical BTC Price Data:
2024-06-30 06:00: $61,750
2024-06-30 07:00: $62,010
2024-06-30 08:00: $61,500
2024-06-30 09:00: $61,020
2024-06-30 10:00: $61,200
Supplementary Information:
- Current market volatility: 75% annualized,USDT market cap remains stable
- Large on-chain transfer: >$1B USDT transferred out at 11:15 on 2024-06-30
News Summary & Interpretation:
- 2024-06-30 10:30: Crypto influencer on Twitter reports suspected exchange insolvency, potentially triggering market panic and short-term BTC sell-off
- 2024-06-30 11:15: On-chain data indicates significant fund movement, possibly reflecting panic sentiment or flight to safety
Prediction Task:
Based on the above, forecast BTC price trends from 12:00 to 18:00 on 2024-06-30}
Expected Output:
{2024-06-30 12:00: $60,500
2024-06-30 13:00: $59,800
...}
Prompt Design for Training the Reasoning Agent
Input:
{Please summarize the categories of news events that are likely to significantly impact BTC price movements within the next 12 hours:
- Major breaking events (e.g., exchange insolvency, project exit scams)
- Abnormal large-scale on-chain transfers
- Regulatory news (positive or negative)
- Technical upgrades or mainnet launches
Expected Output Format:
{
"Short-term Impact Keywords": ["insolvency", "fund movement", "emergency announcement"],
"Long-term Impact Keywords": ["regulation", "compliance", "mainnet upgrade"]
}}
Prompt Design for Training the Evaluation Agent
Input:
{ Based on the following information:
- Significant discrepancies observed between actual and predicted BTC prices within the forecast interval
- Historical textual data:
-
2024-06-30 10:30: Twitter influencer reports suspected exchange bankruptcy
-
2024-06-30 11:15: Telegram group notes large USDT transaction
-
2024-06-30 11:45: User reports partial withdrawal restrictions
Question:
Were any important pieces of information overlooked or excluded from the news filtering logic? If so, please propose an improved version of the filtering strategy. }
-
3.2.2 The Advantages and Necessity of Private Domain Data
Compared to public news and traditional data sources, CO datasets demonstrate significant advantages across multiple dimensions, particularly suitable for quantitative research on cryptos combined with large language models (LLMs) and intelligent agents.
First, CO datasets possess notable real-time capabilities. Through proprietary technical means, they efficiently scrape text information from various private domains related to cryptos (including Telegram groups, Discord channels, WeChat groups, etc.) at a minute-level frequency. This private data channel can capture market dynamics, sentiment changes, or potential unexpected event earlier and more sensitively than public news media, thereby providing strong support for building forward-looking predictive models.
Second, CO datasets have a rich and structured tagging system. Each text data is equipped with detailed metadata, including: the specific crypto or trading pair involved in the text; sender identity information, such as whether they are opinion leaders (KOLs), project team members, or ordinary users; and multi-dimensional tags such as sentiment tendencies, risk signals, and group chat sources.
This high-density feature design naturally aligns with large language models and inference-based intelligent agent frameworks, significantly enhancing the model's ability to understand complex text information and infer potential impacts. At the same time, this also provides a foundation for customizing personalized crypto datasets, allowing users to flexibly filter and combine data based on different cryptos, KOLs, or community characteristics, thereby enhancing the model's predictive relevance and practicality in specific trading instruments and community environments.
Additionally, CO datasets have undergone systematic text deduplication, cleaning, and normalization before data entry, effectively avoiding redundant information and significantly reducing the consumption of model input tokens. This not only helps alleviate resource pressure during the training of large language models, reducing training costs, but also enhances the efficiency and stability of the model during the inference and generation processes.
Therefore, leveraging CO datasets and combining them with the large model and agent inference framework proposed in this paper can provide a solid foundation for innovative applications in crypto quantitative trading, market risk control, intelligent research and investment, etc.


评论 (0)