
Tại Altius, chúng tôi dành rất nhiều thời gian để nghĩ về hiệu suất. Chúng tôi hình dung một thế giới nơi cơ sở hạ tầng blockchain hoạt động giống như các hệ thống giao dịch tần suất cao - song song hóa, ưu tiên bộ nhớ và tránh tối đa các thao tác nhập/xuất (I/O) không cần thiết.
Vì vậy, khi chúng tôi bắt đầu nghiên cứu mã nguồn của Paradigm’s Reth, đó không chỉ là sự tò mò. Chúng tôi đang đánh giá cách tích hợp một cách gọn gàng một lớp trạng thái (state layer) mô-đun, có khả năng mở rộng dưới các công cụ EVM hiện có, hỗ trợ công việc của chúng tôi về Lưu trữ Có khả năng Mở rộng Song song (Parallel Scalable Storage - PSS) và phân mảnh Merkle trie phân tán.
Những gì chúng tôi phát hiện khiến chúng tôi bất ngờ.

Tắc nghẽn không ngờ tới
Chúng tôi nhận thấy một điều kỳ lạ khi kiểm tra cách Reth xử lý truy cập cơ sở dữ liệu, đặc biệt là trong các thao tác đọc trạng thái. Ngay cả đối với các thao tác tra cứu tài khoản đơn giản, công cụ này lại thực hiện các lệnh gọi cơ sở dữ liệu không cần thiết, những lệnh gọi hoàn toàn có thể được rút ngắn và bỏ qua.
Trong các hệ thống như Reth, nơi trạng thái được lưu trữ trong một Merkle-Patricia Trie (MPT) và được hỗ trợ bởi ổ đĩa, mỗi lệnh gọi cơ sở dữ liệu thừa đều gây ra chi phí thực sự về độ trễ của ổ đĩa. Trong trường hợp của Reth, chúng tôi nhận thấy có một lượng đáng kể truy cập ổ đĩa không cần thiết.
Vì vậy, chúng tôi đã mở Issue #14558 trên kho lưu trữ GitHub của Reth. Chúng tôi ghi lại hành vi này, giải thích tác động đến hiệu suất và thậm chí đề xuất nhiều tối ưu hóa khác nhau, một số sử dụng chính các cấu trúc dữ liệu hiện có của Paradigm.
Những gì chúng tôi phát hiện - và cách chúng tôi cùng cải thiện!
Sau một phản hồi nhanh chóng trên issue GitHub với một gợi ý không khả thi, chúng tôi không nhận được thêm cập nhật nào. Vì vấn đề này rõ ràng đang cản trở mục tiêu của chúng tôi, chúng tôi quyết định tự mình đi sâu vào mã nguồn để tìm hiểu. Lưu ý rằng các sơ đồ dưới đây thảo luận về các mục nhập khác nhau trong cơ sở dữ liệu MDBX mà một tra cứu tài khoản điển hình cần truy cập để lấy thông tin cuối cùng cho tài khoản đó. Không ngạc nhiên khi bố cục cơ sở dữ liệu thực tế được thiết kế rất tốt, và bảng AccountsTrie phản ánh cấu trúc MPT của Ethereum. Điều này khiến chúng tôi ngạc nhiên khi phát hiện ra những gì đang diễn ra bên trong. Để tìm hiểu, chúng tôi đã thêm các thông điệp nhật ký theo dõi vào mọi truy cập cơ sở dữ liệu mà chúng tôi có thể tìm thấy và theo dõi từng truy cập cho đến khi hiểu rõ chuyện gì đang xảy ra.
Chúng tôi rất muốn đi sâu vào chi tiết (thêm phần phức tạp), nhưng có lẽ sẽ dễ hơn nếu chỉ nhìn vào sự khác biệt giữa các triển khai của chúng tôi bằng cách xem cách thực hiện việc duyệt cây trie. Một lần nữa, xin cảm ơn bố cục cơ sở dữ liệu, chúng tôi phát hiện ra rằng có các bitmask được lưu trữ trong mỗi nút, cho biết chính xác những gì có hoặc không có trong các nút trực tiếp bên dưới nó. Vì vậy, thay vì duyệt qua các phần lớn của cây trie, chúng tôi chỉ duyệt những gì thực sự cần thiết. Đây là phiên bản Reth v1.3.2:
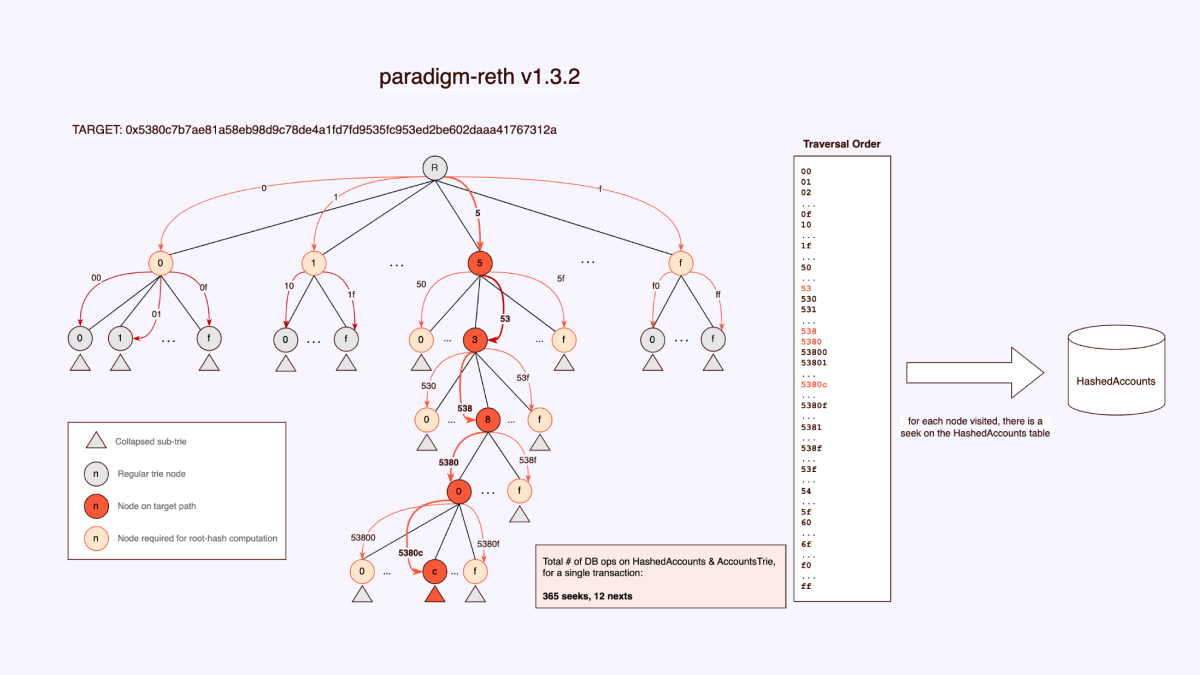
Ví dụ, ở cấp cao nhất, mặc dù chúng tôi biết rằng sẽ cần tất cả các nút cấp 1 để tính toán hàm băm gốc (root hash) sau khi cập nhật MPT, và mặc dù các bitmask hiện có đã cho biết các nút này tồn tại, Reth vẫn tiếp tục tìm kiếm qua từng nút. Không phải là thăm tất cả các nút một cách đầy đủ, nhưng nhiều nút vẫn được truy cập một cách không cần thiết. Hãy chuyển sang giải pháp của chúng tôi. Chúng tôi làm điều đơn giản mà ai cũng mong đợi!
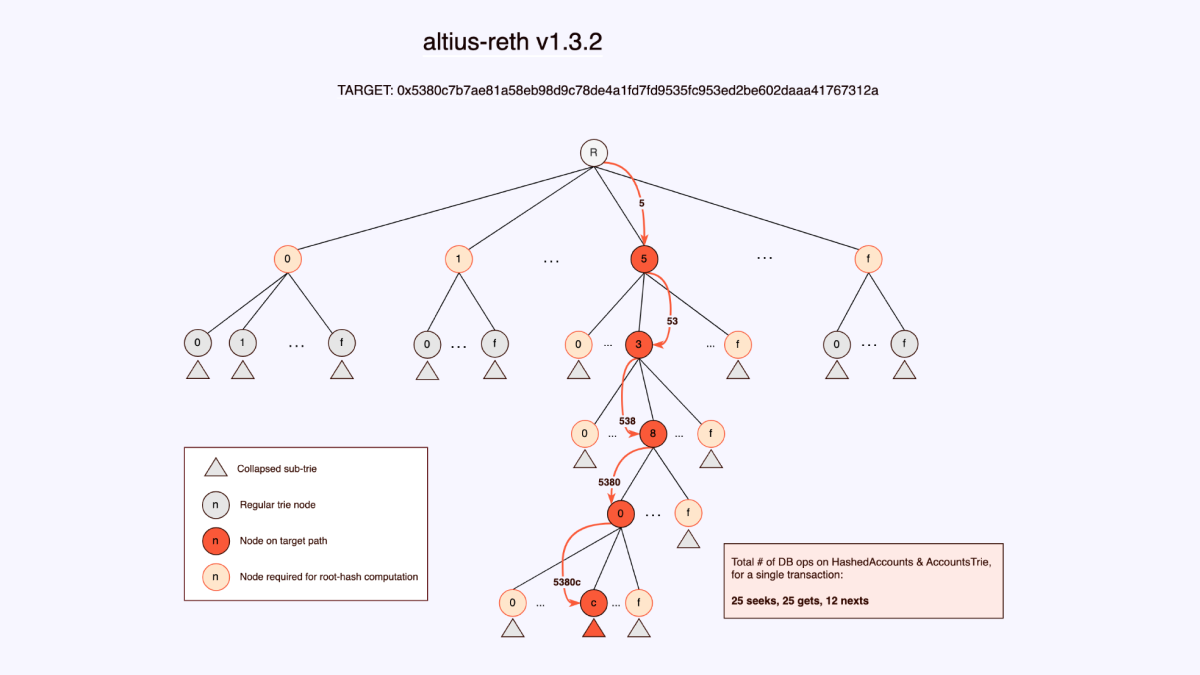
Chúng tôi sử dụng thông tin có sẵn trong các bitmask của mỗi nút để xác định xem nút tương ứng có tồn tại trong bảng HashedAccounts hay không. Ngoài ra, chúng tôi chỉ đơn giản duyệt xuống cây tới tất cả các nút cần thiết để tính toán hàm băm gốc.
Như bạn có thể thấy trong các sơ đồ, số lượng thao tác cơ sở dữ liệu giảm đi một bậc độ lớn. Và như chúng ta biết, mỗi truy cập ổ đĩa mà chúng ta có thể tránh được là yếu tố then chốt đối với tốc độ của bất kỳ tầng thực thi nào. Các sơ đồ trên là kết quả của một giao dịch ngẫu nhiên mà chúng tôi đã theo dõi. Tất nhiên, một giao dịch không phải là số liệu thực tế, vì vậy chúng tôi đã theo dõi từ 500 đến 1000 khối và thấy cải thiện từ 70% - 80% qua các phạm vi khối khác nhau. Nhưng điều quan trọng là các thao tác nhập/xuất thực tế trên ổ đĩa, vì vậy chúng tôi đã phân tích điều đó tiếp theo.
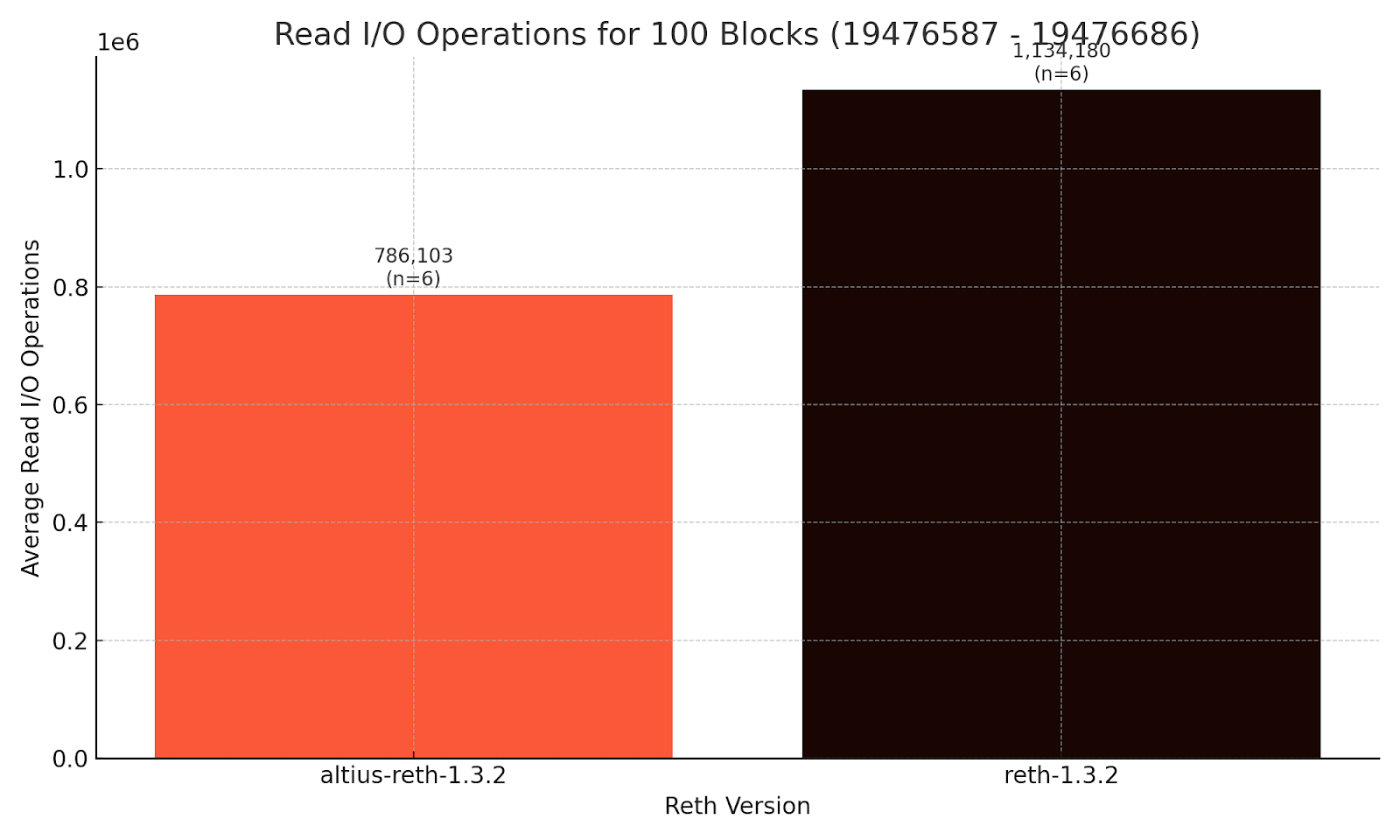
Kết quả thực tế
Việc chuyển đổi các thao tác cơ sở dữ liệu này thành giảm số lượng thao tác đọc (read IOPs) đã khiến chúng tôi kiểm tra hiệu suất khi thực thi 100 khối (từ 19476587 đến 19476686) và sử dụng Linux cgroups để cô lập hiệu suất IOPs của Reth trong quá trình thực thi. Đối với các bài kiểm tra, chúng tôi đã thực hiện 12 lần chạy, đầu tiên xóa bộ nhớ đệm ổ đĩa, cô lập IOPs cho quá trình Reth và cơ sở dữ liệu MDBX trên thiết bị lưu trữ NVMe, sau đó lấy trung bình 6 lần chạy ở giữa (loại bỏ 3 lần đầu và 3 lần cuối theo phương pháp tiêu chuẩn gọi là phạm vi tứ phân vị - IQR). Công việc này được thực hiện trên một phiên bản Amazon Web Services EC2 tiêu chuẩn (i8g.4xlarge). Kết quả là chúng tôi thấy giảm 44% số lượng thao tác đọc IOPs nhờ các tối ưu hóa của mình.
Tại sao chúng tôi lại xem xét vấn đề này ngay từ đầu
Tại Altius, kiến trúc của chúng tôi được xây dựng dựa trên một vài ý tưởng cốt lõi:
-
Thực thi phải song song. Xử lý giao dịch tuần tự không tận dụng được toàn bộ sức mạnh tính toán của bộ vi xử lý, nhưng điều này yêu cầu thông tin tài khoản phải sẵn sàng trước khi một giao dịch cần đến nó!
-
Trạng thái nên được lưu trữ trong bộ nhớ càng nhiều càng tốt và được lưu trữ thông minh.
-
Thao tác nhập/xuất ổ đĩa là kẻ thù của hiệu suất. Đặc biệt là trong điều kiện tranh chấp.
Đó là lý do tại sao chúng tôi đang xây dựng Lưu trữ Có khả năng Mở rộng Song song, bao gồm một triển khai phân tán, ưu tiên bộ nhớ của Merkle trie. Mục tiêu cuối cùng là cho phép các tầng thực thi coi hệ thống của chúng tôi như một hộp đen: nhanh, đáng tin cậy và có thể mở rộng theo chiều ngang. Nhưng để làm được điều đó, chúng tôi cần một ranh giới trừu tượng rõ ràng, và các trừu tượng rõ ràng đòi hỏi hành vi có thể dự đoán từ mã nguồn phía trên. Đó là lý do tại sao, sau khi thấy các mẫu truy cập cơ sở dữ liệu trong Reth, chúng tôi quyết định tự mình sửa chúng.
Điều này mang lại gì
Với một mô hình truy cập tối ưu hóa và nhất quán hơn, công cụ trạng thái của Altius có thể tích hợp bên dưới các client hiện có. Đối với các chuỗi sử dụng Reth, điều này có nghĩa là:
-
Giảm ngay lập tức thao tác nhập/xuất mà không cần thay đổi cơ chế đồng thuận hoặc VM.
-
Hỗ trợ lưu trữ trie phân tán - chạy trạng thái của bạn trên nhiều nút thay vì chỉ một.
-
Cải thiện tính tiện lợi cho nhà phát triển khi thử nghiệm các mô-đun trạng thái một cách riêng lẻ.
Chúng tôi đang tiếp tục xây dựng tầng bộ điều hợp và có kế hoạch mã nguồn mở công việc tích hợp này.
Chúng tôi tin vào hiệu suất mở
Đây không phải là vấn đề danh tiếng. Đây là về hiệu suất thực thi. Bài viết này không phải là để chỉ trích. Nó là một lời mời gọi.
Reth của Paradigm là một thành tựu kỹ thuật tuyệt vời, và một phần lý do nó tồn tại là để cộng đồng có thể đóng góp và hợp tác. Chúng tôi sẽ tiếp tục đưa ra những gì chúng tôi tìm thấy. Và chúng tôi sẽ tiếp tục xây dựng các thành phần mô-đun, mã nguồn mở, cho phép bất kỳ chuỗi nào mở rộng thực thi mà không cần phải xây dựng lại thế giới từ đầu.
Bởi vì cuối cùng, mỗi thao tác nhập/xuất vẫn rất quan trọng.
Cập nhật cải tiến từ đội ngũ Reth
Sau khoảng 3 tuần, trong khi chúng tôi nỗ lực làm việc trên giải pháp của riêng mình, đã có một cập nhật trên issue GitHub. Hóa ra cuộc điều tra và phân tích của chúng tôi đã mở ra cánh cửa cho những cải tiến tuyệt vời. Có vẻ như giải pháp của chúng tôi đi theo một hướng hơi khác, nhưng dựa trên cùng ý tưởng, đội ngũ Paradigm đã thêm các tối ưu hóa tương tự vào Reth.
Là một đội ngũ mới bắt đầu xây dựng với Reth, chúng tôi vẫn thận trọng về mức độ tốt của mình. Chúng tôi thường bắt đầu từ vị trí cho rằng mình sai, và phải có lý do cho cách mà một thứ gì đó được thực hiện. Việc thấy rằng chúng tôi thực sự đúng chắc chắn mang lại cho chúng tôi sự tự tin lớn hơn rằng chúng tôi đang đi đúng hướng!
Chú thích:(1) Trong thuật ngữ MDBX, các bảng được gọi là cơ sở dữ liệu (databases) và cơ sở dữ liệu được gọi là môi trường (environments). Nhưng để dễ hiểu hơn cho những độc giả chưa từng sử dụng MDBX, tôi đã gọi MDBX là cơ sở dữ liệu và môi trường là bảng. Tham khảo: https://pkg.go.dev/github.com/torquem-ch/mdbx-go/mdbx


评论 (0)